AI: The Only Benchmark that Matters
“Not everything that counts can be counted, and not everything that can be counted counts.” — William Bruce Cameron (often misattributed to Einstein)
Thirteen years ago, when I began my journey back into hands-on coding after years of management consulting, I believed that the apex of achievement in our field was the novel algorithm. I spent my evenings poring over arXiv papers, chasing the bleeding edge of model architectures, convinced that the next breakthrough in backpropagation or attention mechanisms would unlock the business value we had all been promised. I was, like many of my peers, building cathedrals—imposing, rigid structures of exquisite mathematical complexity that stood as monuments to human ingenuity but often served no functional parish.
We have spent the last decade worshipping at the altar of the benchmark. MMLU, HumanEval, HellaSwag—these have become our cardinal directions, our means of orienting ourselves in the vast space of artificial intelligence capabilities. I do not disparage this work. There is genuine beauty in the pursuit of the frontier, in the way a well-designed transformer can map the latent spaces of human knowledge with ever-increasing fidelity. The data scientists and engineers who toil to squeeze another percentage point from these evaluations are performing a necessary rite, a kind of digital alchemy that pushes the boundaries of what is computationally possible.
But we must be honest about what we are doing. We are often confusing the map with the territory, the metric with the meaning.
The Cathedral of the Science Project
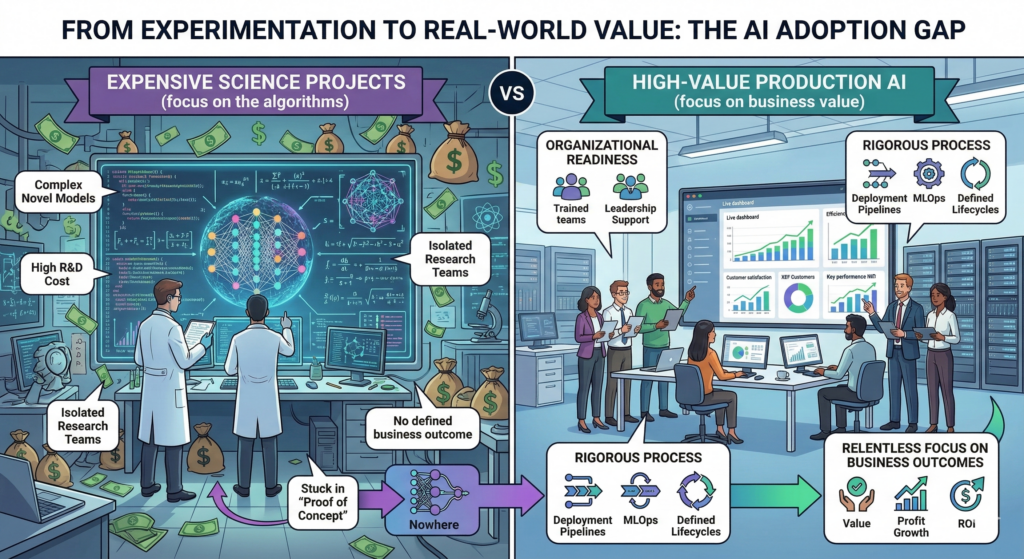
Look closely at the image above. On the left, we see the Expensive Science Project in full flower—a laboratory of isolated brilliance where researchers in white coats (literal or metaphorical) stand before glowing screens displaying complex graph structures, surrounded by floating money bags and the ghostly architecture of neural networks. This is the realm of the Proof-of-Concept, that seductive purgatory where innovation goes to demonstrate its potential while steadfastly refusing to become actual.
I have come to call this the *No-Where Loop*—a strange attractor in the phase space of AI adoption where projects gain enough energy to consume resources but not enough momentum to escape the gravitational pull of experimental irrelevance. The symptoms are universal: Isolated Research Teams working in silos, disconnected from the operational reality of the business; Complex Novel Models selected for their architectural elegance rather than their maintainability; High R&D Costs that scale linearly with the ego of the project leads; and worst of all, No Defined Business Outcome, because the success criteria were written in the language of benchmarks rather than the currency of value.
There is a shadow side to this cathedral-building, and my regular readers know I cannot look away from the shadow. The Science Project serves psychological needs that are rarely acknowledged in quarterly reviews. It offers the illusion of progress without the risk of production. It allows us to remain in the realm of pure potentiality, where our algorithms are perfect because they are untested by the messy reality of user behavior. We become like the alchemists of old, hoarding our esoteric knowledge, speaking in tongues of F1 scores and perplexity, while the business moves on without us.
This is not to say that fundamental research lacks value. Buckminster Fuller’s principle of ephemeralization —- doing more with less until eventually you can do everything with nothing -— requires basic research. But we must distinguish between the R&D that expands the possible and the R&D that merely delays the inevitable. When a project remains in Proof-of-Concept for eighteen months, when the team cannot articulate the specific operational change that will occur upon deployment, we are not doing research. We are performing ritual.
The River of Production
Now look to the right side of that same image. Here we find something far less glamorous but infinitely more powerful: High-Value Production AI.
The lighting is different here—brighter, more natural. The people are not isolated in lab coats but integrated, cross-functional, gathered around dashboards that display not model architectures but business metrics. Customer satisfaction. XEF Customers. Key performance indicators that actually indicate performance.
This is the realm of Organizational Readiness -— a concept I find far more elusive and interesting than any transformer variant. Production AI requires Trained Teams not in the sense of knowing PyTorch or JAX, but in the sense of understanding the Governance Mesh (a concept I have explored previously) that constrains and guides intelligent systems. It requires Leadership Support that extends beyond budget approval to genuine architectural authority, the willingness to redesign processes around AI rather than bolting AI onto broken processes.
Most critically, it requires what we might term as Rigorous Process -— the unsexy infrastructure of Deployment Pipelines, MLOps, and Defined Lifecycles. If the Science Project is a cathedral, Production AI is a river. It flows. It adapts. It carries the weight of state and the velocity of change without collapsing under the Persistence Paradox. Where the cathedral demands perfection before opening its doors, the river accepts that software is liquid, that architecture must be Just-In-Time, and that systems must negotiate their own reality within the constraints of physics (by which I mean policy-as-code), cost ceilings, and data residency requirements that act like immutable laws.
The benchmark here is not MMLU. It is ROI. It is Value, Profit Growth, and the relentless, uncompromising measurement of whether the system returns more than it consumes.
The Only Benchmark
I want to be careful here, because the industry loves false dichotomies. I am not suggesting we abandon the science. The *Universal Abstract Storage* layers we need for true Liquid Software depend on fundamental advances in representation learning. The *ephemeral credential vending* systems that will secure our agentic future require deep cryptographic research. But we must hold these activities accountable to a higher benchmark: the conversion of computational complexity into economic value.
The Only Benchmark That Matters is not found on any leaderboard hosted by Stanford or Meta. It is found in the delta between cost and return, in the specific, measurable improvement of a business capability, in the moment when an AI system stops being a project and becomes a utility—something so integrated into the operational flow that it becomes invisible, like electricity or running water.
Consider the juxtaposition in that image once more. The left side represents potential energy—stored, hoarded, entropic. The right side represents kinetic energy—flowing, directed, purposeful. The arrow between them, labeled “Nowhere,” is the graveyard of AI ambition. It is where we find the models that scored 95% on the benchmark but failed to account for label drift in production. It is where we find the brilliant PhDs who never learned to speak the language of business value, and the business leaders who never learned to ask the right questions of their technical teams.
The Shadow of the Scoreboard
There is a collective shadow at work here, and Jung would recognize it immediately. We benchmark because we are afraid. We are afraid of the messiness of production, the unpredictability of human-in-the-loop systems, the moral weight of decisions that affect real customers with real money. It is safer to optimize for MMLU than to optimize for margin, because MMLU is pure, objective, clean. Margin is messy. Margin requires us to acknowledge trade-offs, to accept that sometimes the simpler model that costs less to run is better than the complex model that wins competitions.
When we hide in the Science Project, we externalize our shadow onto the “business side” (i.e.: those Philistines who “just don’t get it”) who can’t appreciate the elegance of our architectures. But the mirror reveals the truth: we are the ones who have failed to translate, to integrate, to become operational. We have chosen the safety of the lab over the risk of the market.
Let Us Reason Together
So where do we go from here? I propose a new kind of benchmark, one that combines the rigor of scientific evaluation with the reality of operational constraints. Let us measure not just accuracy, but Total Cost of Inference. Not just F1 scores, but Time-to-Value. Not just parameter count, but and Organizational Readiness Index.
The image you see above is not just a description of two modes. It is a choice. Every AI initiative begins as potential energy. The question is whether we have the discipline, the governance, and the humility to convert it to kinetic energy that powers the business forward.
The river is rising. The cathedrals are beautiful, but they are empty unless they serve the people who enter them. It is time to leave the lab, cross the chasm from experimentation to real-world value, and accept the only benchmark that has ever truly mattered:
Does it work? Does it last? Does it return more than it costs?
If the answer to all three is yes, then we have done our job. If not, we are just building very expensive sandcastles, and the tide is coming in.
What are you optimizing for?